Understanding Model Training & Losses: How to Improve AI Performance


Introduction
Training an AI model is more than just feeding it data—it’s a process of optimization, fine-tuning, and minimizing errors to ensure the model performs effectively. One of the key indicators of how well a model is learning is its loss function. But what do these losses mean, and how do they impact model performance?
In this article, we will:
✅ Explain loss functions and how they impact training
✅ Show how loss values change over training iterations
✅ Provide code examples for training a model
✅ Discuss why better training data leads to a better model
1. Understanding Loss in AI Model Training
Loss is a numerical value that represents how far off a model’s predictions are from the actual results. Lower loss values mean better accuracy, while higher loss values indicate the model is struggling.
Types of Loss Functions
🚀 Mean Squared Error (MSE) – Used in regression problems, measures the average squared differences between actual and predicted values.
🚀 Cross-Entropy Loss (Categorical/Binary) – Used in classification problems, measures how different the predicted probabilities are from the true class labels.
🚀 Huber Loss – A mix between MSE and absolute error, useful for models that need robustness against outliers.
2. Code Example: Training a Simple Model & Observing Loss
Let’s train a simple neural network using Python and PyTorch. This example demonstrates how loss values change over epochs.
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
# Sample training data
X = torch.tensor([[1.0], [2.0], [3.0], [4.0], [5.0]])
y = torch.tensor([[2.0], [4.0], [6.0], [8.0], [10.0]])
# Define a simple linear model
class LinearModel(nn.Module):
def __init__(self):
super(LinearModel, self).__init__()
self.linear = nn.Linear(1, 1) # One input, one output
def forward(self, x):
return self.linear(x)
# Initialize model, loss function, and optimizer
model = LinearModel()
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
# Training loop
loss_values = []
for epoch in range(100):
optimizer.zero_grad()
outputs = model(X)
loss = criterion(outputs, y)
loss.backward()
optimizer.step()
loss_values.append(loss.item())
if epoch % 10 == 0:
print(f'Epoch [{epoch}/100], Loss: {loss.item():.4f}')
# Plot the loss over epochs
plt.plot(loss_values)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Loss Curve Over Training')
plt.show()Interpreting Loss Output
During training, we’ll observe something like:
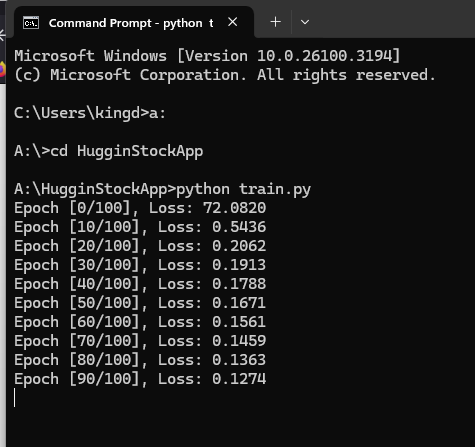
📉 As training progresses, the loss decreases, indicating the model is learning the correct pattern.
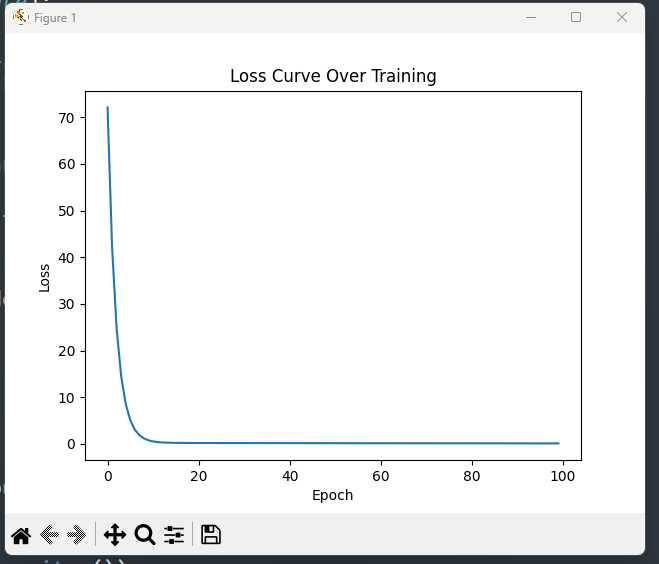
3. Losses & Model Performance
What Does Loss Tell Us?
🔹 High Loss & No Decrease – The model is not learning. The learning rate may be too high/low, or data might be incorrect.
🔹 Loss Decreases Slowly – The model is learning, but training might be inefficient due to sub optimal parameters.
🔹 Loss Drops Too Quickly – Possible overfitting. The model might be memorizing data instead of generalizing.
🔹 Loss Fluctuates Randomly – The learning rate might be too high, or data may contain too much noise.
4. Better Training Data = Better Model
Even the best model architecture will fail if the training data is poor. Some key principles:
✅ High-Quality Data: Ensure data is clean, labeled correctly, and balanced.
✅ Sufficient Diversity: More diverse data helps generalization.
✅ Proper Data Augmentation: Introduce variability in training data without changing meaning (e.g., rotated images for computer vision models).
✅ Avoid Data Leakage: Ensure training data doesn’t contain future information or repeated test samples.
5. Optimizing Model Training for Better Losses
Hyperparameters to Tune
🛠 Learning Rate: Too high = unstable training, too low = slow learning.
🛠 Batch Size: Larger = more stable, smaller = more variance but faster updates.
🛠 Number of Epochs: Too many = overfitting, too few = underfitting.
🛠 Regularization (Dropout/L2): Helps prevent overfitting and improves generalization.
Example: Adjusting Learning Rate
optimizer = optim.SGD(model.parameters(), lr=0.001) # Lower learning rateA lower learning rate can smoothen training curves, preventing instability while ensuring steady progress.
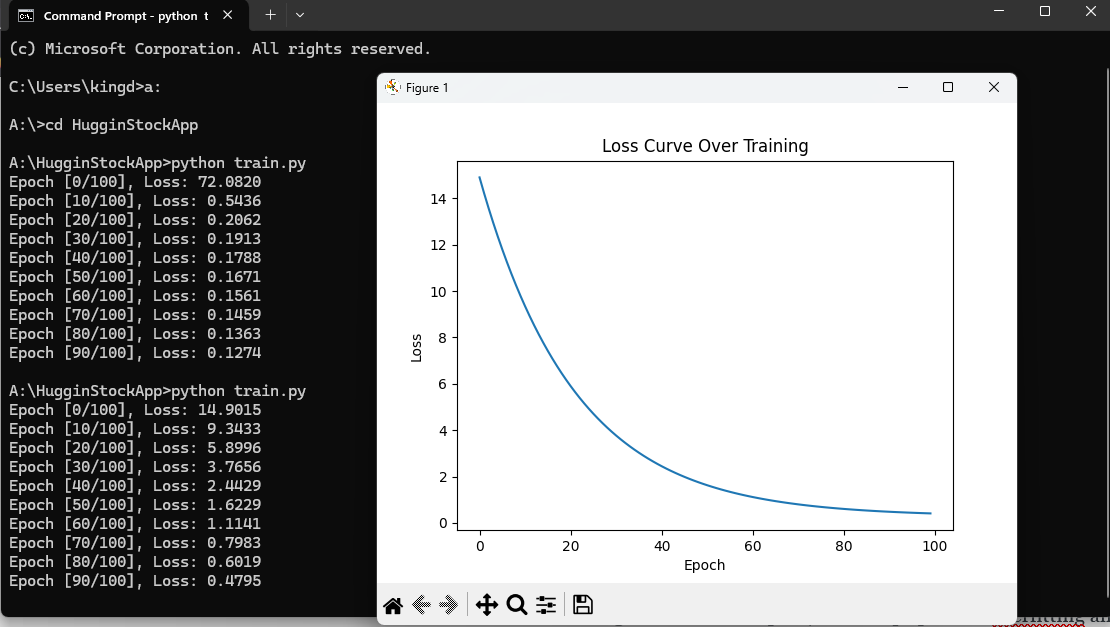
Conclusion: Training Smart for Stronger AI
Training an AI model isn’t just about throwing data into an algorithm—it’s a process of fine-tuning, optimizing loss, and ensuring high-quality inputs. Understanding loss values helps refine performance, and ensuring proper training data leads to models that generalize well in real-world applications.
🚀 Need help building and optimizing AI models?